서 론
음성 장애의 첫 증상 중 하나인 애성(hoarseness)은 음성의 질적 변화와 높낮이, 크기의 변화를 의미하며, 의사소통에 대한 제약과 음성과 연관된 삶의 질적 저하를 특징으로 한다[1]. 의료진은 애성을 주소(chief complaint)로 내원한 환자들이 가지고 있는 후두음성학적 병리를 찾아내기 위해 청지각적 평가, 음향학적 평가, 후두 내시경 검사, 공기역학적 검사 및 근전도 검사 등 다양한 객관적, 주관적인 검사를 활용한다[2]. 이 중에서 음향학적 분석은 녹음된 대상자의 음성을 음성 분석 소프트웨어의 처리를 거쳐 얻어지는 여러 변수들을 통해 정량적으로 평가하는 방법으로, 쉽고 간단하며 비침습적이라는 장점이 있다[3]. 이러한 이유로 음성의 음향학적인 분석만을 이용해 환자의 음성 장애를 진단하고, 치료 전후의 변화를 정량적으로 평가하고자 하는 시도는 이미 1990년대 후반부터 이루어지고 있었다[4,5].
음성 변화를 호소하는 환자들이 반드시 병원에 내원하지 않더라도, 원격의료(telemedicine)로 불리는 비대면 진료를 통해 일정 수준의 음성 질환의 진단이 가능할 것으로 보이는데[6-8], 스마트기기와 같은 휴대 단말기에 내장된 마이크의 성능 향상과 무선 통신 기술의 보급에 더해, 인공지능과 같은 신호 처리 및 분석 기법의 발달은 음성을 이용한 의학적 활용 가능성을 더욱 높여주었다. 파킨슨병과 같은 운동신경질환(neuromotor disease)에서 환자의 음성만을 이용하여 질병의 진단 및 중증도 예측을 하거나[7,9], 후두음성 질환 환자들과 정상인의 녹음된 음성으로부터 정상 음성과 병적 음성을 성공적으로 분류할 수 있었다[6,10,11]. 과거에는 효과적으로 활용하지 못했던 음성이라는 생체 신호를 의학 영역에서 효과적으로 분석 가능하게 한 것이 바로 기계학습 또는 머신러닝(machine learning)으로 불리는 인공지능(artificial intelligence) 기술로, 최신의 딥러닝(deep learning) 분석 기법의 발전은 그간 정체 되어있던 음성 연구의 질적 향상을 이 루었다.
인공지능 연구는 2016년 알파고의 등장이 그 기폭제가 되었는데[12], 국내 인공지능 분야의 연구가 2015년 대비 2016년에 6배 증가했다는 보고[13]처럼, 의학 연구에도 인공지능이 활발하게 도입되었으며, 그 흐름이 지속적으로 이어지고 있으나 실제로 임상 진료에 활용되는 사례는 쉽게 찾아보기 어려운 상황이다. 아마도 인공지능 기술에 대한 이해의 부족, 인공지능 기술 성능에 대한 과장 등이 그 요인들일 것으로 생각된다[14]. 아직 인공지능이라는 기술이 임상 적용까지 충분히 이어지지 못하고 있는 현 시점에서, 음성과 인공지능을 이용해 후두음성학적 연구 및 활용을 하고자 하는 의료진과 전문가들은 의료 인공지능에 대한 기본 지식과 이해 능력을 갖추는 것이 중요할 것으로 판단되는데, 이는 범람하고 있는 인공지능 연구들 사이에서 어느 연구 결과가 진정한 임상적 의미를 가지는지에 대한 해석 능력이 요구되기 때문이다.
이러한 배경에서, 본 논문은 인공지능을 잘 모르는 후두음성을 다루는 의료인 및 후두음성학을 전공하는 여러 전문가들에게 기본적인 개념을 설명하여 그 이해를 돕고자 한다. 다만 음성이라는 생체 신호 처리에 있어, 그 분석 방법과 세부적인 용어에 대한 설명이 한편의 종설로 다 담지 못하는 수준의 방대함을 고려할 때 이 논문을 통해 모든 내용을 다루는 것은 불가능하여, 그 간 음성을 이용한 의학 임상 연구에서 주로 활용된 몇 가지 대표적 사례와 알고리즘에 대한 간략한 개념만을 설명하고자 한다. 이를 통해 해당 분야에 대한 사전 지식이 깊지 않더라도, 음성과 관련된 인공지능 연구에 대한 방법론 및 연구 결과의 이해에 조금이라도 도움이 되는 것에 목표를 두었다. 이 논문에 나오는 용어 중 한글 학술용어가 확립되지 않은 인공지능 관련 용어는 국문과 영문을 병기하여 표현하였다.
본 론
의료 인공지능 용어의 정의 및 분류
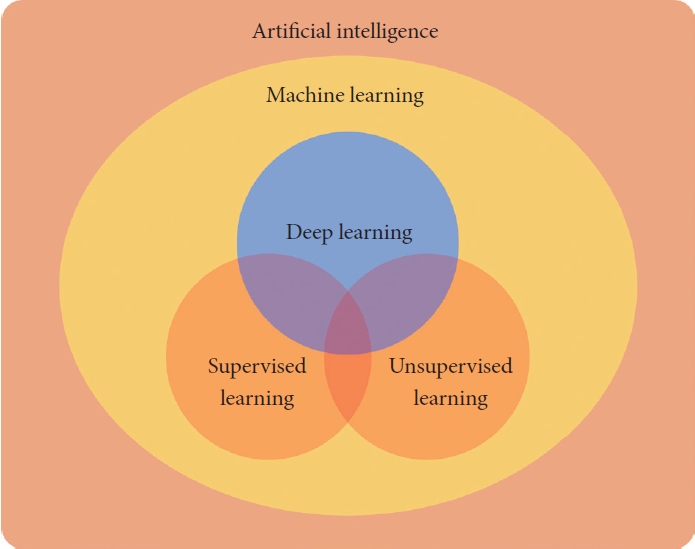
의료 인공지능 연구의 이해를 위해 필수적으로 알고 있어야 하는 것이 각 용어의 정의와 관계다. 우선 인공지능이란, 컴퓨터 공학의 한 분야로 인간의 지능이 일반적으로 요구되는 작업을 수행하는 시스템을 개발하는 분야를 말한다. 이를 달성하기 위한 하위 방법론 중 하나가 머신러닝이며, 딥러닝은 머신러닝 알고리즘 중 하나인 신경망(neural network)이 발전하여 이루어진 방법론이다[15]. 이 논문에서 ‘인공지능’이라고 이야기하는 경우 머신러닝과 딥러닝을 포함하는 개념으로 이해하면 된다(Fig. 1).
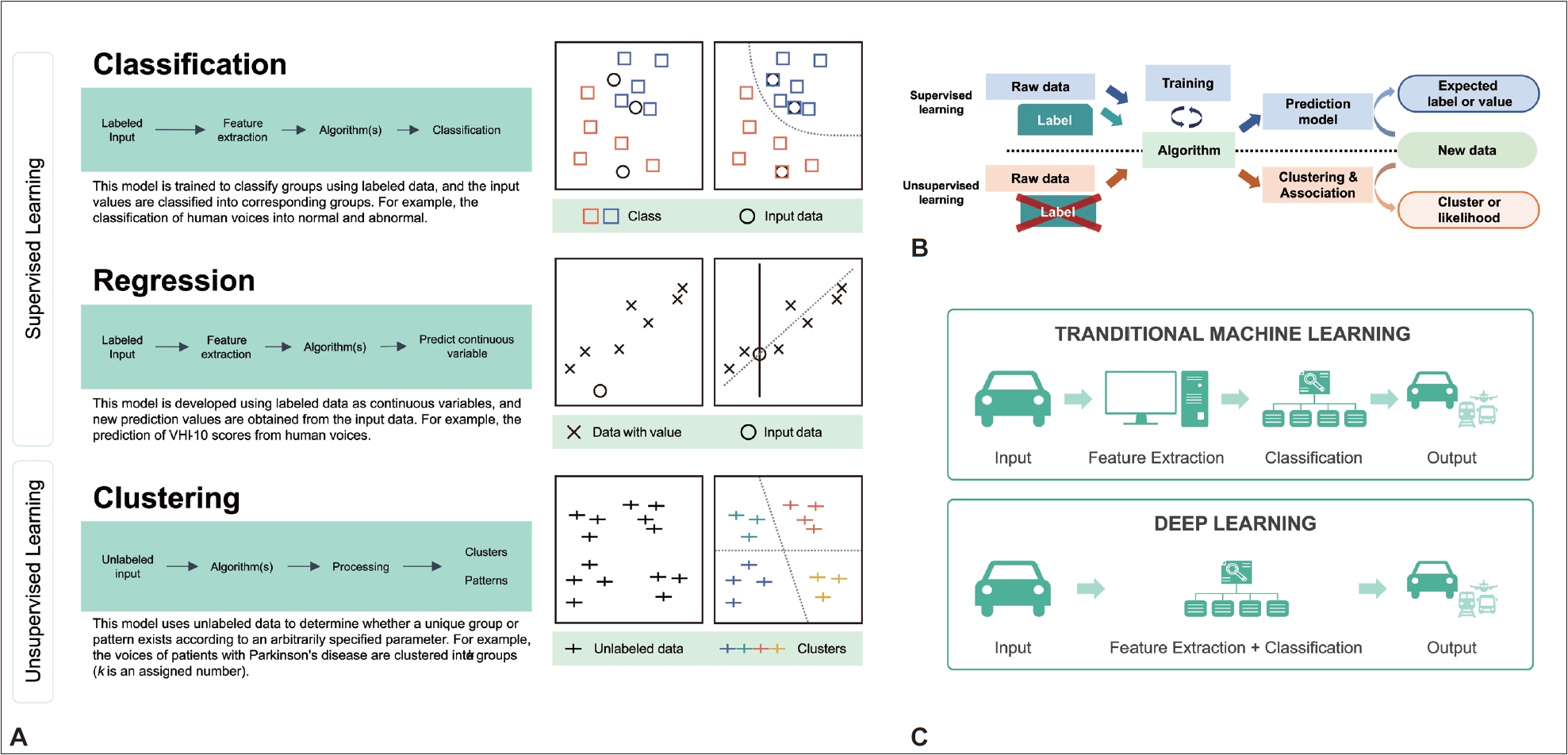
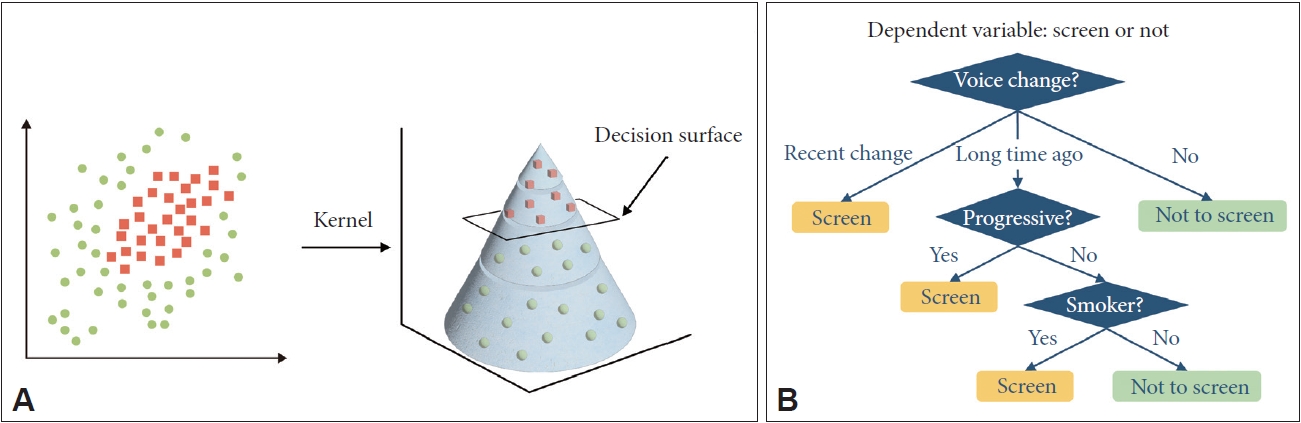
머신러닝과 딥러닝 알고리즘의 숫자는 지금 이 순간에도 계속 늘어나고 있으며, 이러한 알고리즘의 유형은 다시 크게 지도 학습(supervised learning)과 비지도 학습(unsupervised learning)으로 나눌 수 있다. 지도 학습이란 인공지능 모델을 학습시키기 위한 데이터에 정답 값(ground-truth)이 부여(labeled) 된 것이며, 비지도 학습이란 학습 데이터에 정답이 부여되지 않은 방식이다. 연구자들이 인공지능 학습을 통해 예측하려는 지표가 바로 ‘정답’이라고 볼 수 있는데, 후두음성 환자를 예를 들면 후두암, 성대 결절과 같은 특정한 진단명이 될 수도 있고, 음성장애지수(voice handicap index)와 같은 수치형(numeric) 데이터가 될 수도 있다. 지도 학습의 대표적 사례로는 분류(classification)와 회귀(regression)가 있으며, 비지도 학습의 대표적인 사례로는 클러스터링(clustering; 군 집화)이 있다(Fig. 2A). 다만 Fig. 1에서 표현하였듯이 이러한 유형이 절대적으로 이분화 되는 것은 아니어서, 준지도 학습(semi-supervised learning) 및 강화 학습(reinforcement learning)과 같은 유형의 알고리즘들도 존재하나, 이 부분은 본 논문에서 다루지 않는다.
지도 학습과 비지도 학습의 이해
의학 연구에는 검증하려는 가설이 존재하며 인공지능은 그 가설을 증명하는 방법 중 한가지 방법론으로써, 일반적으로 다음 수식처럼 간단하게 정리할 수 있다.
수식 (1)이 일반적인 수학에서 1차 방정식이며 머신러닝에서는 수식 (2)로 표현된다. H는 가설(hypothesis)이며 w는 가중치(weight), b는 편향(bias)을 의미한다. 동일한 문제(가설)를 풀기 위한 함수인 알고리즘 H(x)는 다양하게 존재할 수 있다.
지도 학습은 인공지능 학습에 활용하는 학습용 데이터셋(training dataset)에서 정답 값 y와 입력 값 x를 사전에 알고있는 학습 형태로, 이 두가지를 이용하여 w, b를 결정하는 방식이다. 이렇게 얻어진 수식 H(x)을 검증(validation)하기 위해, 전체 데이터에서 학습 데이터셋을 제외하고 검증을 위해 남겨둔 검증 세트(validation set)를 이용하거나, 전체적인 자료의 숫자가 부족한 경우 이미 학습에 사용했던 자료를 일부 재활용하는 방식인 k-fold 검증 또는 Leave-One-Out 등의 교차 검증(cross validation) 방법을 활용한다. 학습의 방향을 정하는 방법은 알고리즘마다 다르지만 그 원리는 동일하여, 학습을 통해 얻은 모델 H(x)에 검증용 데이터 x를 넣어 y’를 구하고, 이미 알고 있는 정답인 y 값과의 오차를 가장 작게 만드는 방향으로 학습을 이어나가게 된다. 이 과정에서 y’와 y의 차이를 정의하는 함수가 사용되는데, 머신러닝에서는 비용함수(cost function), 딥러닝에서는 손실함수(loss function) 라는 이름으로 사용된다. 모델이 출력하는 y가 수치형 데이터라면 |y’-y|로 두 수치의 차이를 바로 이용할 수 있을 것이며, 진단명과 같은 범주형(categorical) 데이터라면 두 결과가 동일한지 다른지 각각 0과 1로 정의하여 그 차이의 합 을 최소화하는 방향으로 진행할 수 있다. 학습 횟수는 일반적으로 머신러닝에서는 반복(iteration), 딥러닝에서는 에포크(epoch)라고 불리는 횟수만큼 학습이 이루어지면서 w와 b가 갱신된다. 딥러닝과 머신러닝의 용어가 조금씩 차이가 있는 이유는, 일반적으로 딥러닝의 학습 데이터는 빅데이터 수준의 대용량 자료가 활용되기 때문에 학습용 데이터 세트를 한번에 처리하기 어려워 데이터 세트를 지정된 배치 숫자(batch size)로 나누어 처리하게 되면서 발생하는 현상으로, 해당 용어의 관점을 학습 세트 전체에 두느냐 정해진 숫자(배치 숫자)로 나눠진 일부 데이터에 두는냐에 따라 나뉘며, 딥러닝과 머신러닝 알고리즘에 따른 고정된 용어 사용은 아니라고 이해하면 된다.
분류모델은 진단명과 같은 범주형 자료에 대한 대표적인 지도 학습의 유형으로, 입력되는 데이터 x로부터 사전에 범주형으로 정의된 y값들(정답 값, ground-truth; 클래스, class) 중 하나를 얻어내는 과정이다(Fig. 2A). 의료 인공지능 연구에서 활용되는 대표적인 방법으로, 음성을 이용하여 정상음성과 비정상음성이라는 2가지 분류를 해내거나[6], 더 나아가서는 성대 음성 질환의 세부 진단 분류까지 해내는 시도가 이 범주에 속한다[16].
또 다른 대표적인 지도 학습으로 얻어지는 회귀 모델은 의학 연구자들이 익숙한 통계 분석 방식으로, 연속형 변수를 결과로 추정할 수 있다는 측면에서 특정 범주(클래스)를 추정하는 분류 모델과 다른 분석 방식으로 볼 수 있다(Fig. 2A). 음성 지표를 활용한 사례로는, 파킨슨병 환자의 신체 활동들을 스마트폰으로 수집하고 해당 데이터에서 특징값(feature)을 추출한 뒤, 회귀식을 만들어 모바일 파킨슨병 점수(mobile Parkinson Disease Score)를 얻어낸 연구 사례가 있는데, 이 연구에서는 음성의 크기(진폭, amplitude) 값이 회귀식의 변수로 사용되었다[17]. 또한 우울증의 정도를 점수로 구하는 벡 우울척도(Beck Depression Inventory-II)를 예측하는데 음성 지표가 활용된 연구들을 그 사례로 들 수 있다[18,19].
비지도 학습은 학습 데이터에서 오직 x만을 알고 있으며, 사전 정의된 y가 존재하지 않거나, 존재하더라도 이를 활용하지 않는 방식이다(Fig. 2A). 따라서 연구의 목적은 기존에 잘 알지 못했던 새로운 분류체계를 구축하는데 활용한다. 대표적인 클러스터링 방식은 학습 데이터의 입력값 x간의 유사성(similarity)을 이용하여 그룹화하는 것을 의미하는데, 유사성을 구하는 대표적인 방식이 유클리디안 거리(Euclidean distance)라는 수식이다. 이 값은 한 데이터를 2개의 특징값으로 표현하는 2차원 평면에서는 다음과 같이 표현된다.
만약 한 데이터가 갖고 있는 특징값이 2개가 아니고 n개라면 다음과 같은 식으로 표현된다.
앞서 서술한 2차원 평면이라는 의미는 특징값이 2개라는 것으로, 2차원 데이터라고 이야기할 수 있는데, 예를 들면 키와 몸무게 2가지 측정값만을 이용하여 특정 집단의 분류를 시행하는 연구를 그 사례로 생각해볼 수 있다. ‘유사성이 크다’는 의미는 ‘두 데이터의 거리가 가깝다’라는 것으로, 이 사례에서는 ‘두 사람의 키와 몸무게 차이가 작다’라고 이해할 수 있는 것이다.
지도 학습과 달리 비지도 학습은 정답이 없기 때문에, 몇 개의 클러스터(또는 그룹, 클래스 등)로 나눌지 연구자가 설정해야 하며, 유사성이 높은 데이터끼리 묶어가면서 정해진 숫자만큼의 클러스터를 결정지어준다. 따라서 나누는 그룹의 숫자에 대한 정의를 연구자가 정하고 얻어진 결과에 대한 검증을 진행한다. 이렇게 클러스터를 나누는 공식이 학습을 통해 내부적으로 결정되면, 이후에는 마치 지도 학습처럼 새로운 데이터가 들어왔을 때 어떤 클러스터로 배치되어야 하는 지도 예측할 수 있다(Fig. 2B).
비지도 학습의 흥미로운 사례로써 Rusz 등[20]이 2021년에 파킨슨병 진단을 받은 환자그룹을 음성을 이용하여 기존에 없었던 3가지 세부 그룹으로 분류한 연구가 있다. 음성 간의 유사성을 구하기 위해 각 음성에서 켑스트럼 피크 현저성(cepstral peak prominence), 배음대소음비(harmonics-tonoise ratio, HNR) 등을 포함한 8개의 특징값을 추출하여 사용하였으며, 비지도 학습 알고리즘 가운데 중 대표격인 k-평균(k-means) 군집 분석을 활용하였다. 연구자들은 분류하고자 하는 그룹의 숫자를 2에서 5까지 바꿔가면서 모델을 생성한 뒤 결과적으로 세 그룹으로 분류했을 때 레보도파(levodopa) 의 약물 투약에 따른 음성 장애 호전이 각 그룹간 유의한 차이를 보였기 때문에, 이러한 세 그룹으로 나누는 분류 방식이 임상적으로도 적용 가능한 유용한 방법일 수 있음을 증명하였다[20]. 이러한 사례로부터 비지도 학습은 우리가 그동안 알지 못했던 새로운 분류체계를 만들어내고 질환에 대한 이해의 폭을 넓히는 유용한 수단이 될 수 있음을 알 수 있다.
머신러닝과 딥러닝의 이해
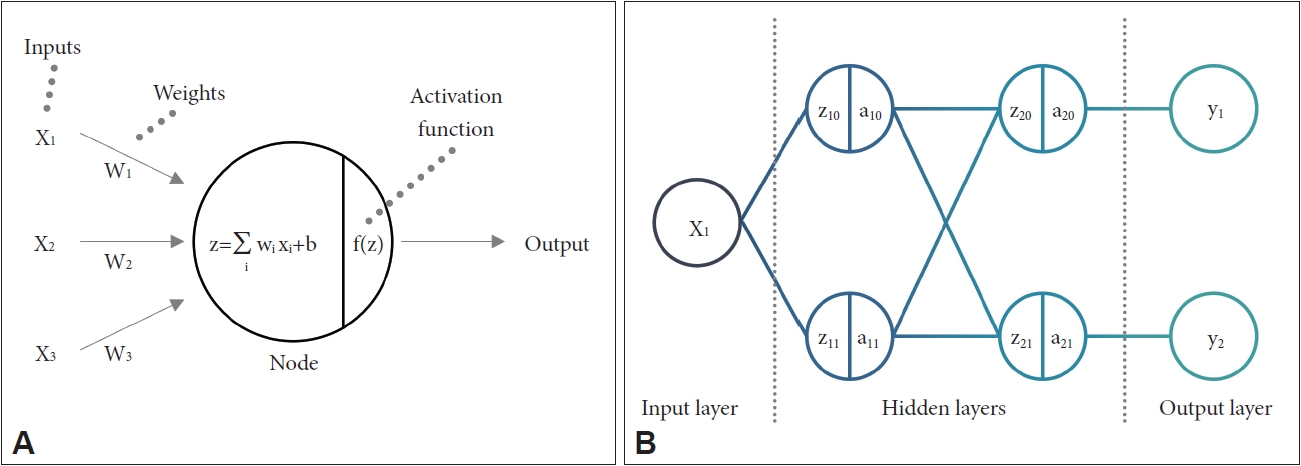
서론에서 서술한 바와 같이 딥러닝은 머신러닝과 다른 방법론이 아닌 머신러닝의 하위 분류에 포함되는 것이다. 머신러닝에서 딥러닝의 근간이 되는 신경망의 개념은 1943년부터 등장하기 시작했고[21], LeCun 등[22]은 1989년 신경망 아키텍처를 이용해 이미지 처리에 주로 쓰이는 컨볼루션 신경망(합성곱 신경망; convolution neural network, CNN)을 최초로 소개하였다. 신경망은 하나의 입력층(input layer)과 하나의 출력층(output layer), 하나 이상의 은닉층(hidden layer)으로 구성되어 있으며, 각 층에는 퍼셉트론(perceptron)으로 구성된 여러 노드(node)들이 존재한다. 각 노드들은 다른 노드와 연결되면서 가중치와 임계값(threshold)을 가지며, 특정 노드에서 가중치와 이전 노드로부터 전달된 값들의 합이 활성함수(activation function)를 거쳐 다음 층으로 데이터를 전송하는 형태이다. 신경망 학습이란 입력값(x)과 출력값(y)을 이용해 각 노드의 가중치와 임계값을 훈련하는 과정이라고 간단히 서술해볼 수 있다(Fig. 3).
딥러닝이란 이러한 신경망 구조에서 은닉층의 여러개로 구성되면서, 그 깊이가 깊다(deep)라는 의미에서 시작된 용어로, 심층(深層) 신경망이라고 불리기도 한다. 신경망의 은닉층을 여러개로 구성하여 그 정확도를 높이고자 하는 시도는 1990년대부터 있었으나, 기울기 소실(vanishing gradient), 과적합(overfitting) 등 여러 문제가 발생하여 성공적인 딥러닝 학습이 이루어지기까지는 많은 시간이 걸렸다. 2006년에 이르러 Hinton 등[23]이 새로운 활성화 함수의 사용 및 노드의 초기화(initialize) 방식을 제안하였고, 2014년에 발표한 드롭아웃 층(dropout layer) 사용 등의 방법론을 통해 그간의 제약들이 해결되었으며[24], 그래픽 처리 장치(graphic processing unit)를 포함한 하드웨어의 발전은 학습에 필요한 병렬처리를 효율적으로 가능하게 함으로써 연산 속도의 문제를 해결해주었고, 많은 수의 노드들을 충분히 학습시킬 수 있는 빅데이터 처리가 가능해짐으로써 최근 수년간 딥러닝 알고리즘들은 성능 면에서 비약적인 발전이 이루어졌다.
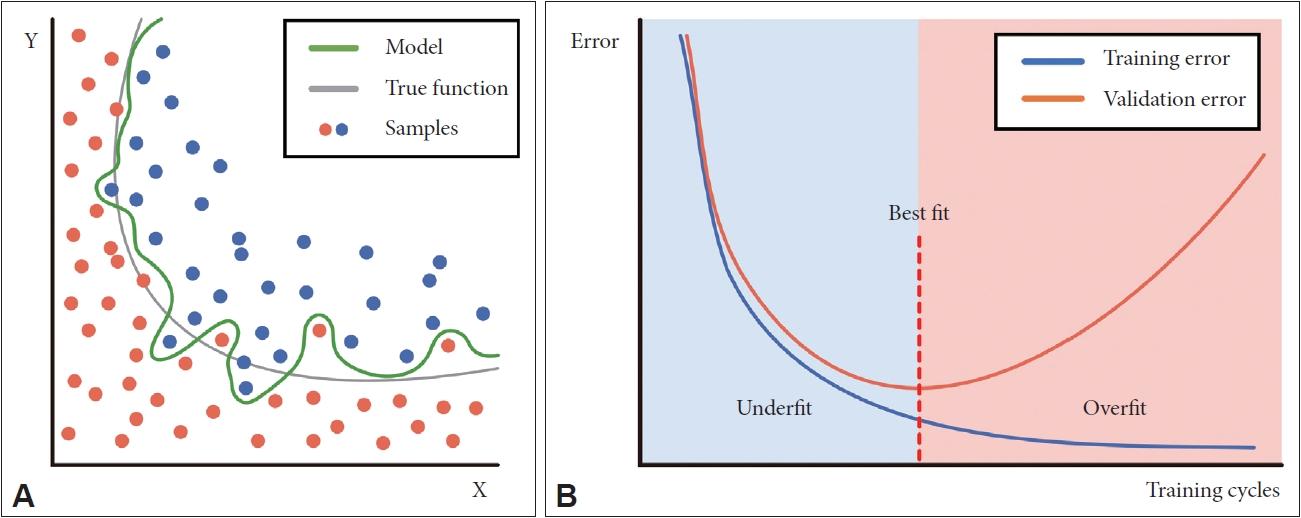
그러나 딥러닝이 머신러닝 중에서 항상 최고의 결과를 보여주는 방식이라고 결론 내릴 수 없는 이유가 존재한다. 딥러닝은 처음부터 여러 층위(multi-layer)로 설계가 가능하며, 학습 가능한 노드의 숫자를 무한정 늘릴 수 있는데, 이 경우 필연적으로 ‘차원의 저주(curse of dimensionality)’가 발생한다. 우리가 구하고자 하는 인공지능 모델이 일종의 고차원 방정식인데, 차원이 늘어날수록 해당 모델을 학습하기 위한 데이터의 양도 함께 늘어나야 한다. 그러나 양적으로나 질적으로 충분하지 못한 데이터로 학습시킬 경우 오히려 성능이 저하되는 결과가 관찰된다. 임상 데이터를 예를 들면, 한 환자에 대해 키, 몸무게, 체질량 지수(body mass index) 등 몇 가지 특징값만으로 데이터를 정의한 상태로 고차원으로 구성된 딥러닝에 적용시킬 경우, 데이터가 갖고 있는 복잡도 보다 모델의 복잡도가 월등히 높아지면서, 학습용 데이터의 분류가 과도하게 이루어지고 실제 데이터의 분류 정확도가 오히려 저하되는 과적합이 발생하게 된다(Fig. 4). 음성으로 예를 들면 딥러닝으로 수십개의 층을 사용하여 수백만개의 노드를 구성해 놓고서 환자의 모음 발화 음성을 다차원 음성 프로그램(Multi-Dimensional Voice Program, MDVP)으로 구해지는 20개의 제한된 변수만을 입력 값으로 사용할 경우, 신경망의 모든 노드들이 적절한 학습이 이루어지지 못하며 과적합이 발생하기 쉽다.
딥러닝의 장점은 모델 구성을 위한 노드의 숫자가 무한히 늘어나면서, 특징 추출(feature extraction) 없이 데이터를 있는 그대로 활용하는 점에 있다. 다만, 특징 추출이 아예 없는 것이 아니라 특징 추출 자체가 모델 학습과 동시에 내부적으로 이루어진다는 것이다(Fig. 2C). 이 과정에서 연구자가 직접 특징을 정의하는 과정에서 무의식적으로 발생하게 되는 편향과 같은 제약 조건이 없다는 점이 딥러닝의 정확도를 대폭 향상시키는 한가지 요인으로 볼 수 있다. 이러한 장점을 살리기 위해서는 충분히 복잡하고, 충분히 많은 데이터를 학습에 사용해야 한다.
정리하자면, 준비된 원천 데이터의 특징값이 적어 낮은 차원의 데이터로 구성된 경우나 학습에 사용되는 전체적인 데이터의 숫자가 충분하지 않다면, 과적합의 발생가능성이 낮은 머신러닝이 적합한 방식일 수 있다. 반면에 딥러닝은 학습하는 데이터의 수가 많고 데이터의 특징값을 제한하지 않는 경우, 즉 이미지 원본 전체, 또는 음성 원본 전체를 활용할 때 더 적합한 방식일 수 있다. 음성 연구로 예를 들면, 음성 연구에서 주로 사용되는 F0, jitter, shimmer 등의 제한된 종류의 파라미터들을 이용할 경우, 이 지표들은 추출된 몇개의 특징값들이라는 점에서 머신러닝에 활용하기 좋은 형태라는 것을 예상해볼 수 있다. 다만, F0, jitter, shimmer, MDVP와 같이 한번 추출한 지표를 이용하더라도, 다른 인구학적, 임상적 데이터를 엮어 동시에 수십가지에서 수백가지의 특징값들로 데이터를 구성하여 학습 데이터의 차원을 충분히 높였다면 딥러닝이 더 좋은 결과를 가져올 수도 있기 때문에 결코 어느 하나의 정해진 원칙은 없다고 이해할 수 있겠다.
음성분석을 위한 머신러닝과 딥러닝의 알고리즘 소개
머신러닝과 딥러닝에서 사용되는 다양한 알고리즘은 그 하나하나를 온전히 설명하기 위해서는 논문 한편의 분량이 필요한 사항들로, 이 논문에서는 간단히 용어 및 사용 범위에 대한 소개 정도로 마무리하고자 한다.
의학에서 활용하는 음성 분석방법과 흔히 음성 인식과 합성으로 대표되는 ‘자연 언어 처리(natural language processing)’ 알고리즘은 조금 차이가 있을 수 있는데, 연구자들이 관심을 가지고 있는 병적 음성의 발생 메커니즘으로부터 기인하는 것으로 본다. 자연어 처리에서는 소리들이 이루어내는 의미(semantics)에 중요성을 두기 때문에 자음과 모음이 모두 중요한 역할을 하나, 대부분의 후두음성 질환은 연속적인 발화(running speech) 보다는 ‘모음’ 발화에 주목을 하게 되는데, 이는 입술, 혀, 구인두 등 자음이 발생되는 조음 기관에 대한 문제보다는 처음부터 ‘음’을 만들어내는 병태생리학적 근원인 성대에 관심을 두기 때문이다. 성대에서 발생시키는 음은 기본적으로 모음이기 때문에, 후두음성학적 병리 상태를 진단하기 위한 음성은 의미적으로는 무의미한 음이더라도 모음 발성일 경우 활용이 가능하다. 음이탈(pitch break), 음성피곤(voice fatigue), 음성단절(break)과 같은 모음만으로는 파악하기 어려운 음성 병리적 현상을 파악하기 위해서는 연속적인 발화를 통해 분석을 해야 하나, 주된 분석에서는 모음 발성만으로 활용이 가능하다는 점에서 인공지능 연구에서 시계열적(sequential)인 분석의 중요성은 상대적으로 줄어들게 된다.
시계열적 분석이 반드시 고려될 필요가 있는 분야가 바로 음성 인식과 합성이다. 만약 ‘안녕하-’라고 인지된 음성 바로 다음에 나올 글자를 예측한다면, 우리는 듣지 않고도 ‘-세요’, ‘-십니까’, ‘-다’ 등의 몇 가지 항목들을 떠올릴 수 있다. 앞서 알게 된 정보가 뒤에서 결정될 사항에 영향을 줄 수 있는 것이 자연어 처리의 중요한 요소가 된다. 그러나, F0, jitter, shimmer 등으로 대표되는 모음으로부터 추출가능한 지표들을 이용한 특성의 분석은 전체적 발화에서 시간의 흐름을 고려하지 않고 부분적인 모음 발화로부터 추출이 가능하다. 따라서 인공지능 연구를 위한 데이터 구성에 있어, 위에 제시한 몇 가지 지표를 이용한 낮은 차원의 입력 데이터를 준비할 수 있었기 때문에 머신러닝으로도 충분히 좋은 결과를 보여줄 수 있었다. 반면 음성 인식이나 합성을 위한 연속되는 발화에서는 자음은 일종의 잡음(noise)과도 같아 자음 음소에서는 주기적인 특성을 찾을 수 없으며, 모음의 경우도 선행 또는 후행하는 자음에 의해 변화하는 현상으로 인하여, 연속적인 발화에서는 전체적인 특징을 한 번에 드러내는 지표를 찾기가 어려울 뿐 아니라, 연속 발화의 각 시점(time)별로 지표가 지속적으로 변화하기 때문에 데이터의 복잡성이 증가하고 분석에 필요한 연산과 메모리 등의 하드웨어 자원이 많이 필요하게 된다. 따라서 딥러닝 기술이 효과적으로 도입되기 전까지 음성 인식과 합성과 같은 과제는 정확도 달성에 제한이 많았으며, 하드웨어의 발전과 딥러닝이 사용되고 나서야 사전 특징 추출 없는 음원(source)의 전체적 활용을 통해 높은 수준의 인식과 합성 결과를 보여주는 이른바 ‘end-to-end’ 모델링이 가능해졌다.
머신러닝에서 음성 연구에 사용되는 대표적 알고리즘은 서포트 벡터 머신(support vector machine, SVM)으로, 선형적(linear) 또는 비선형적(nonlinear)으로 데이터들을 두 부류로 나누는(이진분류, binary classification) 방법이다. 또 다른 대표적 알고리즘으로는 의사결정나무(decision tree)라는 것으로, 특정 질문에 따라 분기하여 그 다음 질문으로 넘어가는 방식이다. 알고리즘에 Boost model 또는 Boost라는 단어가 들어가 있을 경우, 이 범주의 알고리즘이라고 생각할 수 있다(Fig. 5). 2019년에 Kaggle이라는 예측 모델 및 분석 대회 플랫폼의 상위권 팀들의 알고리즘의 순위를 매겨보았더니, 2, 3등이 딥러닝 기반의 알고리즘이 아닌, 그래디언트 부스팅 결정 트리(gradient boosting decision tree) 기반의 모델이 차지했다는 점에서 알 수 있듯이, 기존의 머신러닝 기법들도 딥러닝의 발전에 함께 발전하고 있어, 연구 설계에 따라 충분히 높은 수준의 성능을 보여줄 수 있다는 것을 기억해야한다.
딥러닝에는 CNN, 순환 신경망(recurrent neural network, RNN) 및 이로부터 파생된 수많은 알고리즘이 존재하며, 그 발전 속도를 따라잡기 어려울 정도이다. CNN은 2차원 데이터인 이미지를 처리하기 위해, 기존의 심층 신경망이 1차원 형태의 데이터를 다루던 한계를 벗어나기 위해 도입된 방법으로, 여러 개의 2차원 크기로 정의된 필터(커널)를 통해 2차원적인 이미지에서 공간적인(spatial) 정보를 특징값으로 자동으로 찾아내는 과정을 거친다(Fig. 6) [25]. RNN은 시계열적 처리에 강점이 보이는 신경망으로, 일반적인 신경망들이 항상 출력층으로 향하는 활성화 함수로 이루어진 반면 RNN은 출력층으로 향하는 활성화 함수 이외에도 내부의 은닉층으로 향하는 활성화 함수가 구성되어 각각의 시점(time step) 정보를 포함하고 재귀적인 이용을 가능하게 한다(Fig. 7) [26]. 그러나 최근에는 RNN의 시계열적 특징을 CNN과 합친 gated CNN이 개발되는 등, 고전적인 분류방식으로는 설명하기 어려운 수준의 모델 또한 도입되고 있다[25].
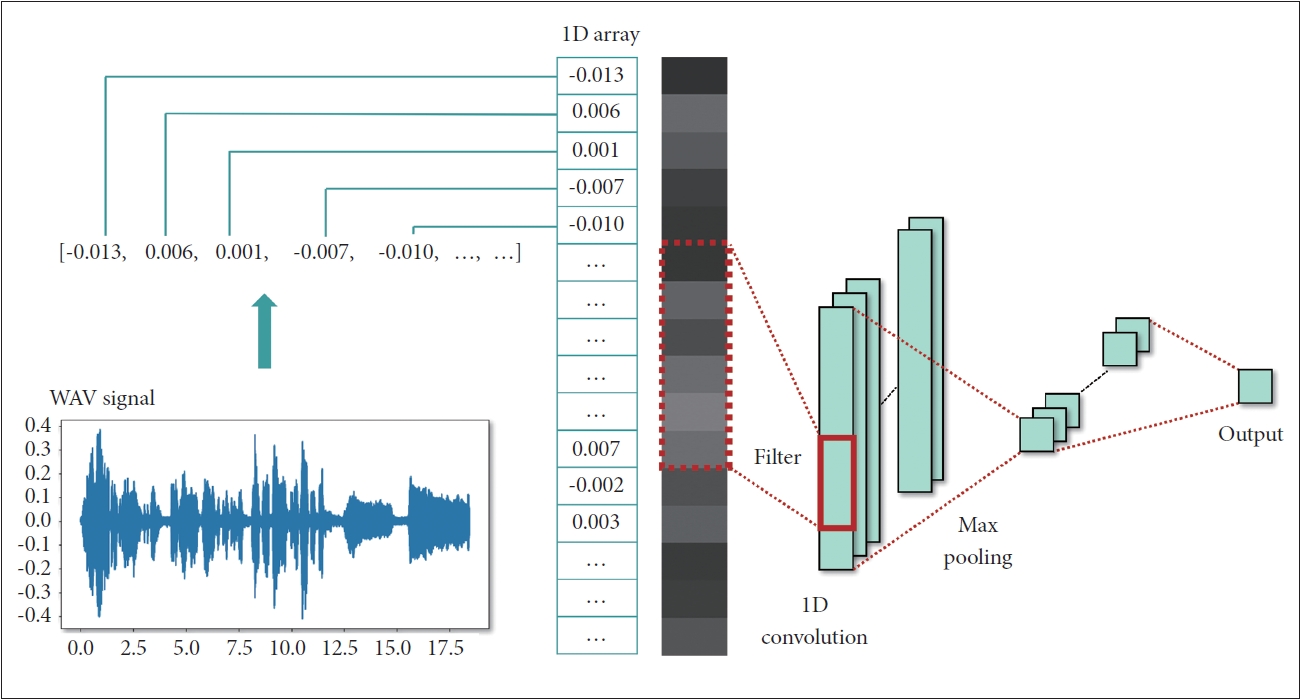
앞서 서술한 바와 같이, 후두음성학적 분석에는 주로 수 초 간의 단일 모음 발화가 활용되며, 연속적 발화를 활용하지 않는 경우가 많아 음성 분석에 있어 시간 정보에 대해 중요성을 둘 필요가 없었다. 따라서 딥러닝을 활용할 때 CNN 계열의 알고리즘이 주로 활용되었는데, 모음 발화 음성을 스펙트로그램 이미지로 변환하거나 각 시점에 대한 멜주파수 켑스트럼 계수(Mel-frequency cepstral coefficients, MFCC)를 이미지로 바꾸어 2D-CNN 계열의 이미지 처리 알고리즘을 사용하는 방법도 가능하였다[27]. 하지만 딥러닝이 가진 장점인 end-to-end 분석을 시행하기 위해 원천데이터인 음원을 바로 사용하는 RNN 계열의 장단기 기억 신경망(long short-term memory, LSTM)이나 게이트 순환 장치(gated recurrent unit) 등을 쓰는 방법도 있다[28]. 또한 음성 데이터의 기본 형식인 WAV 파일은 1차원의 숫자 배열인데, 이 데이터를 마치 높이가 1이고 폭은 음성 데이터의 길이를 가지는 이미지처럼 분석하는 1D-CNN (보통 이미지는 x, y축의 2차원이기 때문에 2D라고 불리는 것에 착안됨) 방식도 음성 분석에 활용되고 있다(Fig. 8) [6,29,30].
음성을 이용한 의료 인공지능 연구의 사례들
그 동안 출판되었던 음성을 이용한 인공지능 연구들은 본 논문에서 소개한대로 머신러닝과 딥러닝을 이용한 연구로 크게 나누어 볼 수 있다. 많은 연구들에서 사용하고 있는 대표적인 데이터셋으로는 자르뷔르켄 음성 데이터베이스(Saarbruecken voice database) [31], 매사추세츠 안이비인후과 종합병원(Massachusetts Eye and Ear Infirmary, MEEI) 음성 데이터베이스[32], 아랍어 음성 병리 데이터베이스(arabic voice pathology database, AVPD) [33] 세가지가 있다. 각 데이터셋은 녹음 환경과 녹음된 데이터의 구조 등이 각기 다르나, Syed 등[34]이 2020년 발표한 메타분석에 따르면, 3개의 데이터셋에서 진행된 연구에서 정상과 비정상 음성의 진단 정확도는 대부분의 연구에서 비슷하게 90% 내외로 보고되었다.
위 3개의 데이터셋은 그 자체로 연구의 대상이기도 하면서 다른 개별 연구에서 얻어진 결과를 검증하는데 사용되기도 한다. Fang 등[35]은 자체적인 음성 데이터셋을 이용한 2019년 연구에서 정상과 비정상 음성을 구분하는 시도를 하면서, 13개의 MFCC 계수(13개의 특징값)를 입력값으로 정의한 딥러닝 모델과 SVM, 가우시안 혼합 모델(Gaussian mixture model)이라는 두개의 머신러닝 알고리즘을 사용하였는데, 학습을 통해 얻어진 모델에 MEEI의 음성데이터를 넣어 외부 검증을 시도한 결과, 오히려 내부 검증 때보다 더 높은 99%에 가까운 성능을 확인할 수 있었다.
앞서 소개한 3개의 데이터베이스는 현 시점에서 이용에 제약이 있는 경우가 있으며, 언어권의 차이 등으로 국내의 연구들은 주로 연구자들이 자체적으로 수집한 기관 내 데이터셋을 활용하고 있다. 국내의 최신 연구들을 살펴보면, Kim 등[6]은 2020년에 정상 목소리와 후두암 환자의 목소리를 분류하는 결과를 보고하였는데, 이 연구에서는 머신러닝과 딥러닝을 동시에 활용하였으며, 머신러닝 분석에는 음성에서 추출된 HNR, jitter 등 14개의 특징값을 사용하였고, 딥러닝 분석에는 음성을 그대로 활용하는 1D-CNN, 음성을 푸리에 변환을 거쳐 얻은 스펙트로그램(spectrogram) 이미지에 대한 2DCNN, 그리고 MFCC 계수를 시간축으로 나열한 이미지를 사용하는 2D-CNN 모델을 각각 활용하였고, 전체적으로 보았을 때 1D-CNN이 가장 높은 정확도(85.2%)를 보였다. 또다른 연구로는 Lee 등[36]이 2022년에 보고한 연구로, 갑상선 수술 전 후의 음성 스펙트로그램으로부터 3개월 후의 GRBAS 점수를 예측할 수 있었다. 이 연구에서는 2개의 CNN을 이용하여 수술 전 후의 스펙트로그램을 입력값(x)으로, GRBAS 점수를 결과값(y)으로 학습시킨 후, 이 두 모델을 LSTM으로 연결하여 시계열적인 특성을 반영시킨 뒤 최종적으로는 3개월 후의 GRBAS 점수 예측을 시켜보았으며, 일정 부분 유의미한 결과를 얻어냄으로써 수술 전 후의 목소리 변화의 시계열적인 분석을 통해 일정시간이 지난 후 목소리 변화의 회복을 예측할 수 있다는 가능성을 제시할 수 있었다. 이외에 본 논문에서 참고한 연구들에서 사용한 알고리즘, 학습을 위한 특징 추출 및 전처리 방법, 그 결과를 딥러닝을 활용한 경우(Table 1)와 딥러닝 외의 머신러닝을 활용한 경우로 나누어 정리하였다(Table 2).
음성을 이용한 인공지능 연구의 한계와 전망
인공지능을 이용한 연구들이 급격하게 늘어나고 유의미한 결과들이 발표되는 가운데, 실제 임상에 적용되고 있는 사례가 많지 않다는 점을 주목해볼 필요가 있다. 가장 큰 문제는 일반화(generalization)가 되지 못하고 있다는 점인데[37], 대표적인 문제는 내부적인 데이터셋으로 만들어낸 알고리즘이 외부 데이터를 이용한 검증을 시도했을 때 보고된 결과에 미치지 못한다는 점이다. 의료 데이터 특성상 완전한 공개가 어려운 경우가 많기 때문에, 특정 기관의 자료만 이용해 만들어진 인공지능 모델에 대한 외부 검증(external validation)이 최근의 인공지능 연구에서는 필수적인 요소로 부각되고 있다[38]. 그러나 무엇보다도 해당 모델을 개발하기 위해 사용한 내부 데이터에 대한 양적, 질적 한계가 중요한 요인일 수 있다. 예를 들어 수집된 데이터의 숫자가 몇백건 정도에 지나지 않은 경우라면 데이터 증강(augmentation)을 시행한다고 하더라도 딥러닝은 물론, 머신러닝 분석을 시행하는 경우에도 과적합이 발생할 가능성이 높다. 학습 데이터의 숫자가 적은 경우 연구자들은 검증을 위한 데이터 세트 구성이 어렵기 때문에 이에 대한 돌파구로써 교차 검증을 사용하여 유효성을 증명하는 경우가 많다. 그러나 이러한 방식으로 유효성을 입증하더라도 결국 내부 데이터만 활용하는 검증 방식이기 때문에 과적합이 일부 경감되는 수준이지 완전히 예방되는 것은 아니다. 데이터 편향에 대한 문제는 항상 대두되는 것으로, 만약 목소리 변화로 병원을 방문한 뒤 후두 내시경 검진을 통해 진단받은 환자의 목소리만을 이용하는 인공지능 모델을 만들었다면, 이 인공지능 모델은 타고난 애성이 있는 목소리지만 점막 병변이 없는 경우를 후두음성질환으로 오인식 한다거나, 후두 병변이 초기라 목소리에 변화가 많지 않은 환자는 정상으로 잘못 분류하는 결과를 가져올 수 있다. 다시 말해서, ‘정상이었던 목소리에 이상을 느껴서 병원을 방문했다’라는 특정 조건이 가지고 있는 편향이 작용하여, 질병의 유무와 무관하게 평소 목소리에 이상을 느끼지 않고 지내는 사람들에게는 해당 인공지능 모델을 적용하는데 적합하지 않을 수 있다는 것을 고려해야 한다.
다른 임상 적용의 한계점으로는 후두음성 질환에 대한 인공지능 모델의 성능이 아직 충분하지 않다는 점이다. 많은 연구들이 정상과 비정상 음성은 비교적 정확한 수준까지 분류 하는 것은 성공하였으나, 세부적인 진단까지 판별하는 경우는 드물뿐더러 그 정확도 또한 높지 않았다. Hu 등[16]은 2021년 연구에서 정상, 성대마비, 연축성 발성장애, 위축성 성대, 기질적 후두 질환의 5가지 다중 분류(multi-classification)를 시도하였는데, 정확도는 임상에서 활용하기에는 아직 낮은 수준인 66.9%로 나왔다. 이 연구에서 주목할 만한 점은 음성을 이용한 진단에 있어 딥러닝 알고리즘의 민감도인 66%는 10년 이상 경력의 후두음성 전문의가 음성만 듣고 진단을 내린 다중 분류에 대한 민감도인 63%, 61% 보다 약간 높은 수준에 그쳤다. 후향적 데이터셋에서 선택 비뚤림이 있을 가능성, 즉 연구자들이 자료 수집 시 해당 질환의 특성이 잘 반영되었을 것으로 판단되는 음성들을 선별적으로 수집했을 가능성이 있다는 점을 고려한다면, 아직은 음성만을 이용해 진단을 해내는 것이 간단하지 않다는 것을 생각해볼 수 있다.
다만, 위의 연구 사례도 연속된 광둥어 발화 녹음 중 /아/모음만을 활용했던 연구이며, 인공지능 모델의 성능은 학습데이터의 양과 질적인 측면에 따라 좌우된다는 점을 고려해야 한다. 다시 말해 음이탈, 음성피곤, 음성단절 등 모음 이외의 발화에서 관찰될 수 있거나, 아직 연구자들이 정확하게 정의 내리지 못했으나 딥러닝이 찾아낼 수도 있는 음성 병리적인 특성을 모두 반영하기 위해서는 단순한 모음 발화 이상의 자료가 필요할 수 있다. 아직은 연속 모음 이상의 음성 자료를 학습용 데이터로 활용한 사례가 많지 않다는 점에서 인공지능 모델의 정확도에 있어 개선 가능한 여지가 남아 있을 것으로 기대된다.
음성 질환의 세부적인 진단의 어려움과는 별개로, 환자 음성에 대한 인공지능의 활용은 점차 증가하는 추세로, 특히 파킨슨병과 근위축성 측색 경화증(amyotrophic lateral sclerosis) 같은 운동신경질환에서 활발하게 보고되고 있다. 단순히 병의 진단이나 분류의 측면을 넘어[7,20] 중증도를 파악하여 의료진의 개입(intervention) 또는 약물 투약 용량과 용법 등에 대한 도움을 주거나[17,20,39], 운동신경질환의 특징인 구음장애(dysarthria) 환자의 음성을 인식하여 일상생활에 편의를 증가시키고[40], 원격으로 음성 재활 치료를 진행하는 등[41] 다양한 목적으로 점차 그 연구영역을 넓혀가고 있다.
또한 최근의 COVID-19로 인한 전 지구적인 감염병의 등장은 비대면 방식으로의 의료 시스템에 대한 수요를 촉발하였는데, 음성만을 이용하여 COVID-19를 진단할 수 있다는 가능성도 보고되는 등[42] 점차 음성을 이용한 의료적 활용의 범위가 늘어날 것임에는 의심의 여지가 없다. 또한 정확한 진단에는 한계를 보인 Hu 등[16]의 연구도 세부적으로 보면, 5개의 범주 중 정상 목소리, 연축성 발성장애의 두 카테고리는 89%, 83%의 높은 정확도를 보여, 전체적으로 분류가 잘 되지 않는 것과는 상반된 결과를 보였다. 사실 음성 전문가도 목소리만 듣고 정상 목소리와 연축성 발성장애는 다른 기질적 질환과 구분하는 것은 어느정도 가능하며, 기질적 질환에 대한 정확한 진단은 후두 내시경으로 확인하지 않을 경우 확진이 어렵다. 즉, 인공지능이 기존에 음성 전문가들이 하던 임상 수준 이상의 기능은 하지 못하고 있다는 이야기이면서도, 반대로 해석하면 어느 수준까지는 음성 전문가들에 대한 모방이 가능하다는 것을 의미한다. 다시 말해, 아직 인공지능의 전체적인 정확도가 낮고 의료진이 후두경이라는 강력한 검사 도구를 사용할 수 있다는 점 때문에 음성을 이용한 인공지능 연구의 필요성을 낮게 볼 것이 아니라, 반대로 인공지능이 더 특장점을 갖고 해낼 수 있는 부분을 찾아 의료진과 음성 전문가들을 돕는 방향으로 발전시켜야 한다는 것을 의미할 수 있다. 예를 들면, 목소리에 문제가 발생한 사람들이 중 조기에 진료 및 진단을 받아야 할 환자를 찾아내 그 치료 시점이 늦어지지 않도록 하거나, 후두음성 질환의 치료 전후 음성에 대한 정량적인 평가를 하고, 질환의 조기 재발이나 악화를 발견하는 등의 의미있는 방향으로 연구를 이끌어 나가야할 것이다.
결 론
의료 분야에 있어 인공지능의 도입은 기존에 수행하던 연구와 다른 방식을 통해 새로운 결과를 도출해내고 있으며, 그동안 몰랐던 새로운 의학적 진단, 치료, 예방의 가능성을 높여가고 있다. 음성은 인체의 주요 생체 신호이자 개인 식별 가능성이 있는 중요한 개인정보로, 비대면 진료 환경에서 더욱 중요성이 부각될 것이다. 인공지능과 음성을 이용한 의학/의료 영역에서의 연구는 아직은 임상에 적용 가능한 수준의 성과를 내지 못하고 있으나, 불과 몇 년 전의 연구들과는 비교하기 어려운 수준의 상당한 기술적 진보를 이룬 것을 확인할 수 있어, 향후 발전 가능성이 더욱 크다고 볼 수 있다. 조금씩 현실화되고 있는 의료 인공지능 시대에 후두음성 전문가들은 인공지능 연구에 대한 기본 지식을 습득하고 적절히 활용할 줄 알아야 하며, 이에 따라 기본적인 개념에 대한 이해가 필수적일 것이다. 이 논문을 통해 비록 심도있는 수준의 설명까지는 다가가지 못했으나, 향후 인공지능과 관련된 음성 연구에 대한 분석과 이해에 중요 요소들에 대해 파악하고, 비판적인 사고를 통해 정확한 분석과 이해를 하는데 도움이 되기를 바란다.