사례 적용 Praat 기반 CSL 대체 자동화 음성분석 프로그램
Two Cases Using the Praat-Based Automatic Voice Analysis Program as an Alternative to CSL
Article information

Trans Abstract
There are a number of voice analysis programs around the world. Domestic voice analysis is performed by relying heavily on specific commercial program. We intend to develop coding for voice analysis using Praat and apply it to clinical practice. This study consisted of Experiment 1 and Experiment 2. Experiment 1 was the development of automated voice analysis coding based on Praat. The coding was largely divided into a recording, an analysis, and a storage section. Experiment 2 was applied to the voice analysis of 2 male patients pre- and post-operation with this coding. The analysis parameters of this coding provided 26 parameters for vowel /a/, nine parameters for sentence analysis, and a total of 4 parameters for voice range profile analysis. In two male patients, the pitch and the intensity increased, the voice quality improved, and the sentence length decreased after surgery. The coding was well made, so the output was good in real time. The code is automated as much as possible to block manual errors and increases convenience and efficiency by generating the result sheet in real time.
서 론
음성분석이 가능한 소프트웨어는 KayPENTAX사의 Computerized Speech Lab (CSL; www.pentaxmedical.com) 및 Multi-Dimensional Voice Program (MDVP), 전 세계 공유프로그램인 Praat (www.praat.org), Tiger DRS사의 Dr.Speech (www.drspeech.com), Paul Milendovic가 개발하고 TF32로도 알려진 CSpeechSP (userpages.chorus.net/cspeech/), GW사의 SoundScope (www.gwinst.com), UCLA 음성학 실험실에서 개발한 VoiceSauce (www.phonetics.ucla.edu/voicesauce), MK Prosopsis사의 VoxMetria (www.mkprosopsis.com/Software/VoxMetria.html), KayPENTAX사의 Visi-Pitch, Oxford Research Wave사의 OperaVOX (http://www.operavox.co.uk), 그리고 MintLeaf software사의 Sonneta (www.mintleafsoftware.com) 등이 있다[1].
이 중 널리 사용되고 있는 프로그램은 MDVP와 Praat이다[2-5]. MDVP는 KayPENTAX사의 Computerized Speech Lab에 포함된 프로그램으로 신뢰도가 높지만 높은 비용 부담으로 병원 혹은 연구소 등에서 주로 사용한다[5]. 이 프로그램이 국내 대다수의 클리닉에 설치된 이유는 본 프로그램을 판매하는 기업이 국내에 존재하고 단순 키 작동으로 실시간 분석결과지를 시각적으로 얻을 수 있다는 점과 정상군의 규준(norm data) 제공으로 정상 및 병리적 음성 비교분석이 용이하기 때문인 것으로 보인다. MDVP 결과를 대용량으로 처리할 때는 매크로 기능이 있는 다른 프로그램(e.g., Praat)을 이용하여 이중으로 처리할 수 있는 반면, Praat은 그 자체 하나의 프로그램 내에서 대용량 분석과 결과 정리가 가능하다. Praat은 해당 홈페이지에서 무료로 내려받을 수 있어 경제적이고 장소의 제한 없이 사용 가능하다[3,5]. 또한 정기적으로 오류를 잡아 업그레이드 버전이 꾸준히 나오고 있어 프로그램의 완성도가 높으며 앞서 언급했듯이 대용량 데이터 처리가 가능한 스크립트 기능이 탑재되어 있기 때문에 음성 연구자들 사이에서는 대단히 높은 호응을 받고 있고 언어치료사들도 많이 활용하고 있는 추세이다[3]. 두 프로그램은 모두 기본주파수(F0), 주파수 변동(jitter) 관련 변수, 진폭 변동(shimmer) 관련 변수, 소음 대 배음비(noise to harmonic ratio, NHR) 등 여러 음성변수의 평균, 표준편차를 제공하고 있으며[5], 특히 Praat에서 MDVP의 동일 변수분석을 제공하는 것뿐 아니라 각각의 프로그램에서의 역치값을 제공하고 있어[6] Praat이 MDVP의 장점을 포괄한다.
MDVP와 Praat 간의 상관을 살펴본 연구에서는 F0 추출에 대해 두 프로그램 간에 강한 상관을 보고하였고[2-4], 합성음 대상 분석에서도 같은 결과를 보였다[7]. 또한 음성장애 중증도에 따른 F0 값은 두 프로그램 간 차이가 크지 않다고 보고되었다[5].
본 연구팀은 이렇듯 전 세계 무료 공유프로그램인 Praat이 있음에도 국내 임상에서는 MDVP만을 사용하여 음성분석을 하고 있는 현실을 주목했다. 음성분석용으로 유일한 MDVP를 사용할 수 없는 특수한 상황이 갑작스럽게 발생하였을 때 임상에서 사용하기 편리한 음성분석 프로그램이 있다면 음성검 사자들에게 큰 도움이 될 것이다. 이에 본 연구팀은 Praat을 기반으로 한 자동화 음성분석 코딩을 개발하여 소개하고자 한다. 본 코딩에서는 기존에 행한 음성검사 행위를 기반으로 모든 과제에 최대한 자동화 처리를 하여 사용자의 업무량을 줄이고, 실시간 분석결과지 출력기능으로 업무의 효율을 높이고자 한다. 저자들은 개발한 코딩을 소개하며 이를 2명의 환자에게 적용한 사례를 보고하는 바이다.
증 례
Praat 스크립트 코딩작업
저자들은 한국 임상 실정에 맞는 음성분석용 Praat 스크립트를 개발하였다. 개발된 코딩은 연구자들의 이름을 따서 KCK_code라고 명명하고자 한다. 본 KCK_code는 3개의 활동영역(녹음부, 분석부, 저장부)으로 구성하였다.
국내 임상에서 행하는 음성검사는 면담, 청지각 평가, 음향 및 공기역학 분석, 자가설문지 등으로 이루어진다. 이 중 음향 분석은 MDVP로 편안한 모음 /아/ 녹음과 분석, CSL로 5개 모음(/아, 에, 이, 오, 우/)과 문장녹음과 분석, voice range profile (VRP)로 점진적으로 음도를 높이는 글리산도(glissando) 방식의 모음 /아/ 녹음과 분석이 이루어진다[8]. 녹음 순서, 방법, 대상 하위 분석프로그램은 개별 병원마다 약간의 차이가 존재할 수 있으나 표준지침을 최대한 반영하여 KCK_code 녹음순서는 최대연장발성의 모음 /아/, 5개 모음 및 문장, VRP로 정하였다. 참고로, 본 연구자는 모음 /아/ 녹음을 편안한 상태의 최대연장발성을 염두에 두었고, 본 코딩을 갖고 Praat을 작동시킬 때 독자들이 이해를 할 수 있도록 Praat 내 버튼의 영문표기를 수용하였다.
녹음부
녹음부는 앞선 3가지 과제를 한번에 모두 담을 수 있게 하였다. 녹음길이(=시간) default 값은 20 MB이고 필요에 따라 사용자가 사전에 변경할 수 있다. 참고로, 20 MB는 스테레오(stereo) 조건에서 220초(≒3분 7초) 녹음 가능하고, 모노(mono) 조건에서는 440초(≒7분 4초) 녹음할 수 있는 값이다[6]. 입력 값을 높이면 녹음시간은 길어지지만 녹음된 파일이 분리 저장되는 단점이 있기 때문에 음성분석을 위해서는 60-100 MB가 적당하다[9]. 녹음길이를 변경하고자 할 때는 Praat objects 창에서 좌측 상단의 Praat을 선택하고 그 하위 Preferences 선택하여 Sound Recording Preference…를 선택 후 Buffer size [MB]에 원하는 값을 입력하면 된다.
본 KCK_code를 실행시키면(Fig. 1A) 첫 화면은 환자등록번호 입력 창이 팝업(pop-up)된다(Fig. 1B). 환자등록번호를 입력 후 ok 버튼(button)을 선택하면 Pause: stop or continue (모음 /아/, 문장, 글리산도 녹음을 합니다.) 창과 SoundRecorder 창이 팝업되고 녹음 작업이 시작된다. 녹음 channel을 mono와 stereo 중 mono로 지정하였고, sampling frequency (샘플링 주파수)는 8000-192000 Hz 중 44100 Hz로 지정하였다.
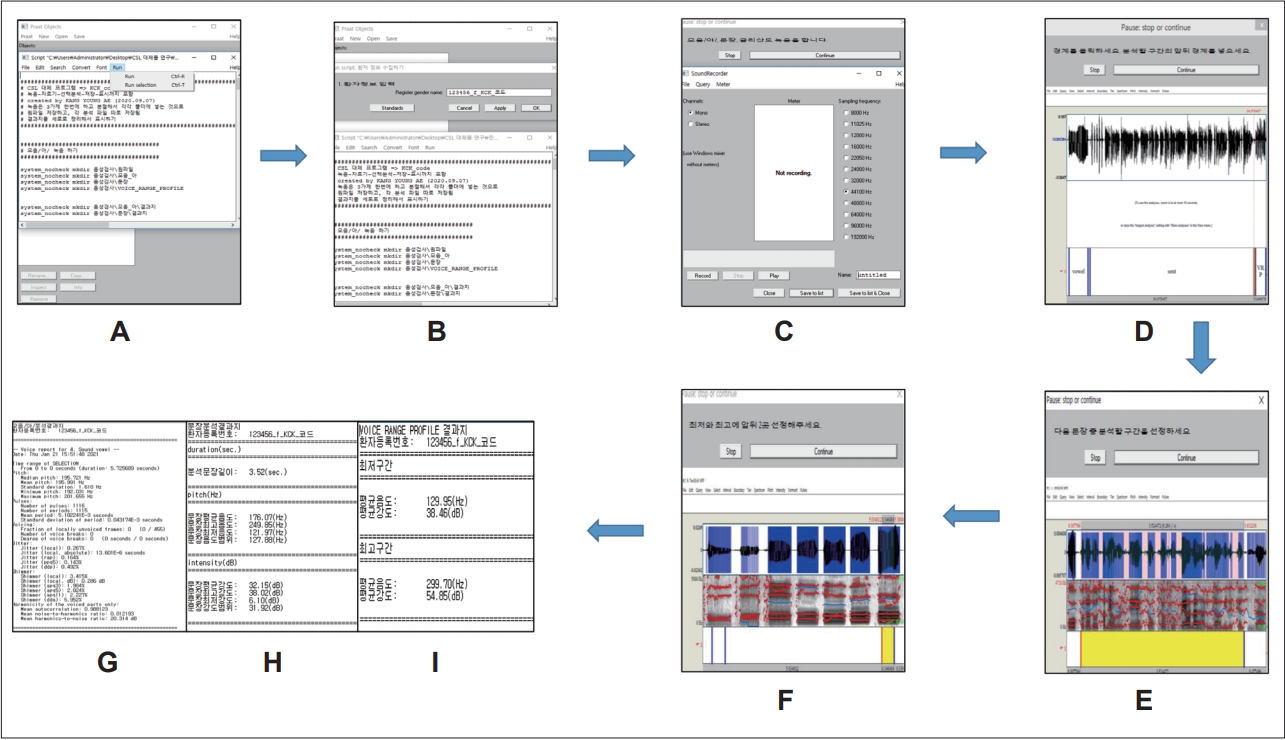
KCK_code workflow. (A) is to open the Praat script and select RUN to start it. (B) is the pop-up screen for patient information input. (C) is the screen in which the recording window and the pause window are popped up. (D) is the screen where the recorded voice file and its text grid file are opened together, the analysis section is selected, and the corresponding tag is attached within the section. (E) is the screen for selecting a part to be analyzed among recorded sentence files. (F) is the screen in which the recorded voice range profile is loaded and each boundary between the lowest and highest section is inserted. (G) is the voice report result for vowel /a/. (H) is the result for the sentence. (I) is the result for voice range profile.
녹음은 SoundRecorder의 하위 Record 버튼을 선택하여 시작한다. 사용자가 샘플링 주파수를 변경하고자 할 때는 Record 버튼 선택 전 SoundRecorder 화면에서 원하는 샘플링 주파수로 선택한다(Fig. 1C). 녹음이 끝나면 Stop 버튼 선택 후 Save to list Close를 선택해주면 녹음된 파일이 Praat Objects 창에 자동으로 옮겨지고 환자입력정보명을 단 Sound 파일이 생성된다. 생성된 음성파일에 해당 TextGrid 파일이 자동 생성되어 Sound와 TextGrid 파일이 동시에 선택된 후 Pause: stop or continue (경계를 클릭하세요. 분석할 구간의 앞뒤 경계를 넣으세요.) 창과 TextGrid 창이 동시에 팝업된다.
분석부
분석구간은 총 3 구간(section)으로 최대연장발성의 모음 /아/ 전체 구간, 문장 전체 구간, VRP의 전체 구간이며, 세 구간을 선정하는 것이므로 필요한 경계(boundary) 수는 총 6개이다. 최대연장발성 모음 /아/ 전체 구간의 앞뒤, 문장 전체 구간의 앞뒤, VRP 전체 구간의 앞뒤에 커서를 넣고 자판의 enter 키(key)를 선택하면 TextGrid 화면에 세로 줄의 경계가 생성된다. 결과적으로 화면에 보이는 것은 6개의 세로 줄로 나누어진 7개의 구간이다. 모음 /아/ 구간은 두 번째 구간이고, 문장구간은 네 번째 구간, VRP 구간은 여섯 번째 구간이 된다. Pause 창의 continue 버튼을 선택하면 선정된 2, 4, 6구간에는 순차적으로 구간정보명(vowel, sent, VRP)이 자동 기록되고 본 구간 분리 창은 닫힌다(Fig. 1D).
생성되는 폴더는 총 4개(원파일, 모음_아, 문장, VOICE_RANGE_PROFIE)이며, 녹음된 전체 내용은 원파일 폴더에 하나의 전체 파일이 저장되고, 구간을 나눈 음성파일들은 각각의 해당 폴더에 ‘환자등록번호_구간정보명’으로 저장된다(Fig. 2).
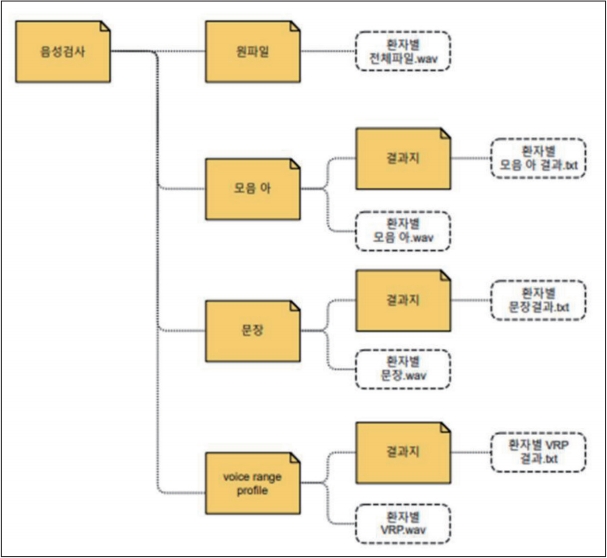
Hierarchy of created folders. The folder of voice evaluation is created. And in it, four folders, namely, raw file, vowel, sentence, and voice range profile folder are created. A recorded voice wav file is stored in the raw file folder, and the corresponding voice wav file and result sheet are stored in each other result sheet folder.
특별히, 최대연장발성 모음 /아/ 구간을 선택할 때는 묵음구간이 들어가지 않도록 wave signal pulse 신호 앞뒤를 정확하게 선택하길 권한다. 다른 구간(sent, VRP)들은 분석을 위해 파일을 다시 불러오는 2차 분석구간 선정과정을 코딩해 두었지만 모음 /아/의 경우는 분석구간 과정을 줄여 바로 구간선정으로 분석이 모두 이루어지도록 한정시켰기 때문이다. 또한 서두에 언급한 대로 녹음순서 중 5개 모음 녹음 분량은 문장 구간에 포함시키면 된다. 보통 5개 모음을 분석하는 이유는 포먼트(formant) 분석을 하기 위함이다. 하지만 병리적 음성의 F0가 불안정하여 현재 기술로는 모음의 정확한 포먼트 추출이 어려우므로 모음의 포먼트 분석결과를 신뢰할 수 없다. 그럼에도 다수의 모음을 녹음-저장하는 이유는 추후 음향분석 기술이 발전하여 병리적 음성의 포먼트 분석이 가능해질 때를 대비하기 위함이고 현재 본 코딩에서는 모음의 포먼트 분석결과를 제공하지 않는다.
구간분리 창이 닫히고 연이어 sent_TextGrid 창과 Pause: stop or continue (다음 문장 중 분석할 구간을 선정하세요.) 창이 팝업된다(Fig. 1E). 열린 파일에서 분석할 구간을 정하고 앞뒤 각각 경계를 넣고 Pause 하위 continue 버튼을 선택하면 완료되어 sent_TextGrid 창이 닫히고, 새로운 VRP_TextGrid 창과 Pause: stop or continue (최저와 최고에 앞뒤 2곳 선정해주세요.) 창이 팝업된다(Fig. 1F). 최저음도와 최고음도 발성 구간에 강도와 음도가 안정적인 지점에 각각 경계 두 개씩 넣어 최저와 최고 분석구간을 선정하고 Pause 창에 continue 버튼을 선택하면 모든 분석작업이 완료된다.
저장부
분석구간 작업을 완료하면 자동으로 분석이 이루어지고 결과지가 저장된다. 모음 /아/ 분석변수는 Praat이 제공하는 Voice Report의 26개 모든 변수를 담았고(Fig. 1G), 문장 분석변수는 9개 변수로, 문장길이, 음도(평균음도, 최고음도, 최저음도, 음도범위), 강도(평균강도, 최고강도, 최저강도, 강도범위)이며(Fig. 1H), VRP 분석변수는 최저와 최고 구간에서 각각 평균 음도/강도로 총 4개의 변수를 추출하였다(Fig. 1I). 본 코딩은 KCK-code 전문이며 Supplementary Material (in the online-only Data Supplement)에 실었고 저작권 등록(160171-0004040)을 완료하였다. 본 코딩의 텍스트 파일이 필요한 경우 저작권협회에서 내려받을 수 있다.
증례 보고
개발된 본 KCK_code를 환자의 음성 분석에 이용하였다. 이비인후과 두경부 전문의로부터 음성장애로 진단받고 미세후두수술을 받은 2명의 남성 환자를 대상으로 수술 전후 음성분석을 KCK_code로 실시하였다. 음성녹음은 수술 전후 1개월 내에 이루어졌으며 대상자의 정보는 Table 1에 제시하였다. 참고로 PHQ-9는 우울 척도 설문지(Patient Health Questionnaire-9)로 9점 이상은 <우울감 있음>으로 진단된다[10]. 분석은 모음 /아/의 음질분석(Voice Report), 문장 및 VRP 분석을 실시하고 수술 전후 사례자별 기술통계를 제시하였다. 문장은 <가을> 문단 중 두 번째 문장(‘무엇보다도 산에 오를 땐 더욱 더 그 빼어난 아름다움이 느껴진다’)을 분석 문장으로 선택하였다.

Voice sample subject information
대상자 2명의 후두미세수술 전후 음성분석결과로 다음과 같다(Table 2). 모음 /아/의 음질 평가 중 대표변수만을 기술하면, 사례 1의 수술 전 F0는 92.84 Hz, jitter 0.41%, shimmer 3.49%, HNR 19.63 dB, NHR 0.01이었고, 수술 후 F0는 121.35 Hz로 수술 전보다 상승한 반면 jitter 0.25%, shimmer 1.59%, NHR 0.00로 수술 후 감소했다. 사례 2는 수술 전 F0는 111.56 Hz, jitter 0.35%, shimmer 2.35%, HNR 25.89 dB, NHR 0.00이었고, 수술 후 F0는 125.52 Hz로 수술 전보다 상승한 반면 jitter 0.34%, shimmer 1.86%, NHR 0.00로 감소했다. 대상자 모두 수술 전보다 수술 후 F0는 상승하였고 음질 관련 변수는 호전되었다.

Analysis results of voice pre- and post-operation in two patients
문장분석결과, 사례 1의 수술 전 문장길이 6.72초, F0 101.37 Hz, 최고/최저 F0 각 235.72/61.33 Hz, 해당 문장의 강도는 평균 65.27 dB이었다. 수술 후 문장길이 5.11초, F0 114.57 Hz, 최고/최저 F0 각 165.75/61.88 Hz, 해당 문장의 강도는 78.19 dB이었다. 사례 2의 수술 전 문장길이 5.02초, F0 113.86 Hz, 최고/최저 F0 각 141.49/81.83 Hz, 해당 문장의 강도는 77.48 dB이었다. 수술 후 문장길이 4.30초, F0 119.23 Hz, 최고/최저 F0 각 144.53/89.54 Hz, 해당 문장의 강도는 84.39 dB이었다. 두 사례 모두 수술 전보다 수술 후에 문장길이는 약간 감소한 반면 F0와 강도는 상승하였다.
VRP 결과, 사례 1의 수술 전 최고 구간의 평균음도 201.42 Hz, 평균강도 88.33 dB, 최저 구간의 평균음도 68.75 Hz, 평균강도 75.98 dB이었다. 수술 후 최고 구간의 평균음도 239.04 Hz, 평균강도 92.67 dB, 최저 구간의 평균음도 112.71 Hz, 평균강도 87.99 dB로, 수술 전보다 수술 후에 최저 및 최고 구간의 음도와 강도 수치가 모두 상승하였다. 사례 2의 수술 전 최고 구간의 평균음도 315.05 Hz, 평균강도 91.50 dB, 최저 구간의 평균음도 101.37 Hz, 평균강도 84.88 dB이었다. 수술 후 최고 구간의 평균음도 240.73 Hz, 평균강도 91.62 dB, 최저 구간의 평균음도 117.32 Hz, 평균강도 86.76 dB로, 수술 전보다 수술 후에 최고 구간의 음도는 낮아진 반면 최저 구간의 음도와 강도는 약간 높아졌다.
고 찰
고가임에도 불구하고 상용화 음성분석 프로그램을 사용하는 이유는 분석의 신뢰도가 확보되었다고 믿기 때문이다. 그래서 새롭게 소개되는 분석 프로그램은 기존에 사용된 프로그램과 상관을 확인하는 과정을 거친다.
Praat은 많은 선행연구에서 이런 검증을 거친 프로그램이다. Praat을 MDVP 및 Dr.Speech와 비교할 때 노이즈(noise)에 대해 가장 강한 면역 시스템(immune system)을 보인다고 평가한다[1]. 이는 Praat과 MDVP 간 F0 추출은 매우 유사한 결과를 보이지만 jitter와 shimmer에 차이를 보인 점에서도 알 수 있다[2-5,11] Praat, MDVP 및 TF32 간 상관조사에서 F0 추출은 세 프로그램 간 차이를 보이지 않았으나 jitter 변수에서 유의미한 차이가 보고되었다[4]. Praat과 MDVP 간 변동률 추출에 낮은 상관을 확인한 연구는[5,11] 변동률 변수를 두 프로그램을 넘나들면서 비교하기보다는 동일 분석 프로그램에서 살펴보길 권고했다. 이처럼 음성분석 프로그램 간 비교 선행연구는 많이 있으며, 공통적인 결론은 F0 추출은 같으나 변동률 결과는 차이가 있다라는 점이다. 하지만 언급된 선행연구들은 모두 사람 목소리 대상 분석결과이다. 즉, 분석 샘플에 노이즈가 들어있으며 이를 어떻게 처리하는가에 따라 변동률 결과에 차이를 초래한다.
반면, 합성음 대상 변동률 조사연구[12]에서는 알고리즘(algorithm) 간 주파수 변동률의 차이가 존재하지만 이는 신호 길이 차이(different length of signal)로 설명되는 소소한 부분이라고 했다. 분석 오류를 줄이고 결과의 정확도를 높이기 위해서는 절대적 최대 피크 검출(absolute maximum peak detection)이 잘 되어야 한다. 이런 점이 병리적 음성에서 일괄되게 진행된다면 프로그램 간 차이는 발생하지 않을 것이다. 하지만 사람 음성에 존재하는 노이즈는 불규칙적이고 비일관적이다. 더욱이 장애 음성에 있는 노이즈는 더욱 불규칙 적이므로 분석 창의 크기에 영향을 주고 분석 창의 영향은 구간 내 최대 피크 검출에 영향을 준다. Praat 개발자들도 이 점을 인지하고 Praat 매뉴얼(voice 5. Comparison with other programs)[6]에 이런 차이를 불러오는 원인을 MDVP의 peak picking 방식과 Praat의 waveform matching 방식 간의 분석 창 변화에 따른 노이즈 영향으로 기술하였고, 노이즈 없는(non-noise) 합성음 대상에서 jitter 변수를 추출한 결과를 MDVP와 비교해 볼 때 Praat의 분석력이 더 안정적임을 입증하였다[7] 이러한 Praat과 MDVP 간 jitter 차이는 병리적 음성일수록 즉, 노이즈가 많을수록 간격이 커짐을 알 수 있다[5].
다른 연구자가 본인이 개발한 특정 음성분석용 스크립트를 기본 Praat 프로그램에 실행버튼을 연결시켜(plug-in) 판매하는 사례도 등장하고 있다[13]. 그만큼 Praat이 음성분석용으로 널리 사용되고 있고 Praat 안의 모든 분석변수 및 통계적 계산력이 상용화된 음성분석 프로그램과 같기 때문일 것으로 추정된다. 본 KCK_code에서도 추후 더 많은 변수 및 분석 개발법을 보완 후 실행버튼을 Praat에 연결시켜 사용자 편의를 높일 예정이다.
본 연구에서는 상용화된 음성분석 프로그램을 대체할 수 있는 자동화 음성분석 프로그램을 구현하기 위해 Praat이란 범용 프로그램을 기반으로 자동화 음성분석 코딩을 완성하였다. 자동화 작업을 많이 적용하여 수동분석의 오류를 차단했으며, 임상에서 바로 사용할 수 있도록 실시간 결과지를 생성할 수 있게 하여 사용자 편리성을 확보하였다. Praat은 스크립트로 제어 가능한 프로그램이므로 본 코딩을 기반으로 대용량 분석에 적용하여 연구에 활용할 수도 있다. 본 KCK_code는 기본적인 음성분석 기술만을 담았기에 추후 장애음성의 정밀한 분석을 위해서 분석기법(e.g., normalization, smoothing, window overlapping analysis etc.) 및 분석변수(e.g., cpp, cpps, LTAS slope etc.) 개발이 계속 이루어져야 할 것이다. 연구의 제한점은 분석결과를 음성치료 전후 혹은 음성분석 전후 시각적 비교가 용이하도록 그래픽을 제시하지 못한 점이다. 이는 Praat의 Picture 창을 통제하여 사용할 수 있는 방법을 추후 제안하고자 한다. 현재 국내 음성연구 및 음성장애 분야의 역사를 비추어 볼 때 본격적으로 국내 기술 기반의 음성분석 프로그램이 개발되길 바라는 바이다.
Supplementary Materials
The online-only Data Supplement is available with this article at https://doi.org/10.22469/jkslp.2021.32.2.87.
Acknowledgements
This work was supported by research fund of Chungnam National University.
Notes
Conflicts of Interest
The authors have no financial conflicts of interest.
Authors’ Contribution
Conceptualization: Young Ae Kang. Data curation: Jae Won Chang. Formal analysis: Young Ae Kang. Investigation: Young Ae Kang. Supervision: Bon Seok Koo. Writing—original draft: Young Ae Kang. Writing—review & editing: Young Ae Kang. Approval of final manuscript: all authors.